
BONUS: Get your complete, step-by-step guide to increasing traffic to your website in 4 proven steps.
Have you ever wondered what happens when you google something? Or did you just chalk it up to magic?
My 5-year-old son thinks automatic doors are magic. I’ve even seen him walk up to a door and when it doesn’t open he’s shocked. But how do you explain something like automatic doors to a 5-year-old? No matter how you put it, he’s going to think it’s magic AND that it’s just supposed to work every single time.
What’s funny about this is that we adults are like that with search engines. When we search for something, we expect perfect results every time. When we get something remotely unrelated, we get a little annoyed. We expect Google and other search engines to just work or happen – like magic – hardly taking into consideration how frickin’ awesome technology is.
What Google does behind the scenes is really cool – and complicated. Here is their explanation of what happens: How search works. This is especially eye opening if you invest in SEO (search engine optimization) services.
Here is our own simplified version of what happens when you google something.
From the searcher’s perspective, it all starts with entering a search phrase in the Google text field and clicking Google Search, or I’m Feeling Lucky (if you’re one of those types of people). Google then returns the relevant results to your search.
But before any of that is possible, a lot of things must happen in order for Google to know what results to show you.
So here’s the quick and dirty overview of how it works:
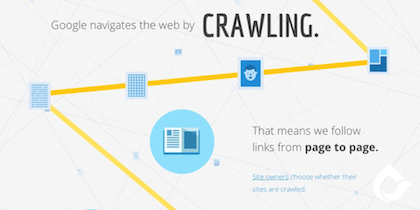
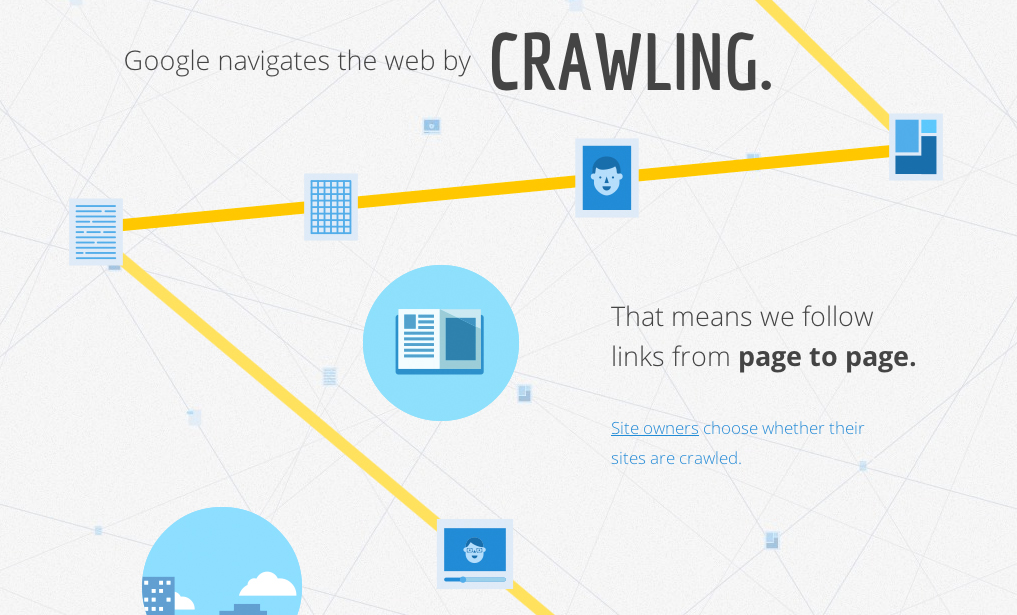
Google needs to know what pages actually exists out there.
The way Google does this is with robots or “spiders.” Yes, much like the those crazy machines in the Matrix. Well maybe not so much like that, but it’s good for visuals. These Google robots constantly “crawl” through the internet and index webpages into its database. Notice I said Web pages – Google looks at each page as it’s own entity.
When Google finds a page and indexes it, a cached version of that page is saved into it’s database. Think of a cached page as a snapshot or screenshot of the page as it exists in that particular moment.
There are 2 tools that webmasters will use to help assist Google and their robot crawlers:
- Site maps: This is basically a document that is uploaded to Google and tells the robots what pages exists on your site, where they are at, and how often they are updated.
- robot.txt: This is a text file the tells the robots what to index and what not to index.
If changes are made to a page, those changes will not be recognized by Google until the crawlers come back and re-index the page and save it into the database. That is why it takes a little bit for the changes you make to take effect in Google. The frequency at which your pages are crawled really depends on your site, but typically it’s about a couple weeks to a month.
You might also like: 10 ways to fix your website and grow your business
How does Google know what results to return?
This is where all the magic happens. We could get really deep here, but I want to keep this simple.
The key factor is relevance, among others. So let’s back up a bit to visualize how this works:
Let’s say Google has just indexed billions of Web pages and saved them into its database. Then you preform a search with a specific phrase. What happens next is Google takes the phrase you entered and goes into its database and returns a list of what it thinks is the most relevant pages to your search… And it does an amazing job to say the least.
But how does it know what pages are the most relevant? Here is a list of what Google takes into consideration when determining relevance:
- The Content – Google loves words. When it’s indexing a page, it looks at the words on the page and determines the topic of the page. It also looks at the words on the page to see if the keywords exists in the content that you entered into your search.
- Title Tag – The title tag is the content that you see at the top of your browser, in the tab. It is also the headline that is used when Google returns its results. Again, Google looks to see if the keywords in your title tag match the keywords in your search.
- Description – The description is the paragraph text that you see in the results that Google returns. Google is going to look to see if there are any keyword matches in this as well.
- URL – This is the Web address of your page. Google is going to look at the keywords used here as well.
- Backlinks – Backlinks are other, external, web pages that are linking to your page. With backlinks, Google looks at a lot of factors like: what is the relevance of the page link, how popular is that page, and many others.
This is just a short list of some of the factors that Google takes into consideration when finding the relevance of its indexed pages to your search.
How does Google rank the results that are returned?
This is another area that we could get really in-depth, but for the sake of this article we’ll keep it light.
When Google indexes a page and takes all the factors in to consideration (like the ones mentioned above), it basically ranks the page against all the other pages that would rank for that particular keyword. Then, when a search is performed, it loads all the results in order of rank. This is also known as the SERP – Search Engine Results Page.
Again this is a very high-level explanation of how all this works, but I hope it’s shined some light on how search engines rank websites and maybe gave you an idea or two on how to be more findable on the Web.
Have something to add? Tell us in the comments.


How friggin amazing technology is…? Watrya a 10 yro… Google’s only job Is Searches, well Google Search atleast, and Relevant Results are Irrelevant. The technicalities of How they do it, Is Irrelevant, only Results are relevant. If I want to search for Hugh Jackman, showing results for Hugh Hefner Is Irrelevant… But that’s what Google Search does, and BTW in realty it’s not Google Search anymore it’s Google Keyword Search. Google breaks down the searches into individual words and searches individually. Sure you’ll find results about Hugh Jackman but also others resulting about anything with Hugh in it. Which is Irrelevant.
Some retards would ask me, Well can You do better? No I can’t, but my dedication isn’t searches either. if it was my field then Yes, I’d perfect it. I’m a truckdriver, how I pickup and deliver loads is Irrelevant, getting the loads delivered safely and on time is relevant. I get paid to do my job. I’m not a load finder or planner, just a driver. Granted searches are free but the search dept gets paid by Google to perfect and engineer their search engines to peak precision. Tbh in the early 80’s when I 1st started using Google, if they didn’t have any results, they said No Results or You might be interested In, today they just show whatever They Think is relevant to the search…
Ya know seriously, that’d be like you or I going to, Idk Red Lobster and ordering crab legs and they bring you a plate of Crab Rangoon… You’d look at the plate then them and they’d say, Oh we didn’t have crab legs but we thought you’d be interested in this… Or better yet maybe they’d bring you Chestnut Linguini, bcuz Google does breakdown words and will give results starting with the 1st letters, and Crab Legs does start with C&L..